Как и обычная библиотека коллекций Scala, библиотека параллельных коллекций содержит большое количество операций, для которых, в свою очередь, существует множество различных реализаций. И так же, как последовательная, параллельная библиотека избегает повторений кода путем реализации большинства операций посредством собственных “шаблонов”, которые достаточно объявить один раз, а потом наследовать в различных реализациях параллельных коллекций.
Преимущества этого подхода сильно облегчают поддержку и расширяемость. Поддержка станет простой и надежной, когда одна реализация операции над параллельной коллекцией унаследуется всеми параллельными коллекциями; исправления ошибок в этом случае сами распространятся вниз по иерархии классов, а не потребуют дублировать реализации. По тем же причинам всю библиотеку проще расширять– новые классы коллекций наследуют большинство имеющихся операций.
Ключевые абстракции
Упомянутые выше “шаблонные” трейты реализуют большинство параллельных операций в терминах двух ключевых абстракций – разделителей (Splitter) и компоновщиков (Combiner).
Разделители
Задача разделителя Splitter, как и предполагает имя, заключается в том, чтобы разбить параллельную коллекцию на непустые разделы. А основная идея– в том, чтобы разбивать коллекцию на более мелкие части, пока их размер не станет подходящим для последовательной обработки.
trait Splitter[T] extends Iterator[T] {
def split: Seq[Splitter[T]]
}
Что интересно, разделители Splitter реализованы через итераторы– Iterator, а это подразумевает, что помимо разделения, они позволяют перебирать элементы параллельной коллекции (то есть, наследуют стандартные методы трейта Iterator, такие, как next и hasNext.) Уникальность этого “разделяющего итератора” в том, что его метод split разбивает текущий объект this (мы помним, что Splitter, это подтип Iteratorа) на другие разделители Splitter, каждый из которых перебирает свой, отделенный набор элементов когда-то целой параллельной коллекции. И так же, как любой нормальный Iterator, Splitter становится недействительным после того, как вызван его метод split.
Как правило, коллекции разделяются Splitterами на части примерно одинакового размера. В случаях, когда требуются разделы произвольного размера, особенно в параллельных последовательностях, используется PreciseSplitter, который является наследником Splitter и дополнительно реализует точный метод разделения, psplit.
Компоновщики
Компоновщик Combiner можно представить себе как обобщенный Builder из библиотеки последовательных коллекций Scala. У каждой параллельной коллекции есть свой отдельный Combiner, так же, как у каждой последовательной есть свой Builder.
Если в случае с последовательными коллекциями элементы можно добавлять в Builder, а потом получить коллекцию, вызвав метод result, то при работе с параллельными требуется вызвать у компоновщика метод combine, который берет аргументом другой компоновщик и делает новый Combiner. Результатом будет компоновщик, содержащий объединенный набор. После вызова метода combine оба компоновщика становятся недействительными.
trait Combiner[Elem, To] extends Builder[Elem, To] {
def combine(other: Combiner[Elem, To]): Combiner[Elem, To]
}
Два параметра-типа в примере выше, Elem и To, просто обозначают тип элемента и тип результирующей коллекции соответственно.
Примечание: Если есть два Combinerа, c1 и c2 где c1 eq c2 равняется true (то есть, они являются одним и тем же Combinerом), вызов c1.combine(c2) всегда ничего не делает, а просто возвращает исходный Combiner, то есть c1.
Иерархия
Параллельные коллекции Scala во многом созданы под влиянием дизайна библиотеки (последовательных) коллекций Scala. На рисунке ниже показано, что их дизайн фактически отражает соответствующие трейты фреймворка обычных коллекций.
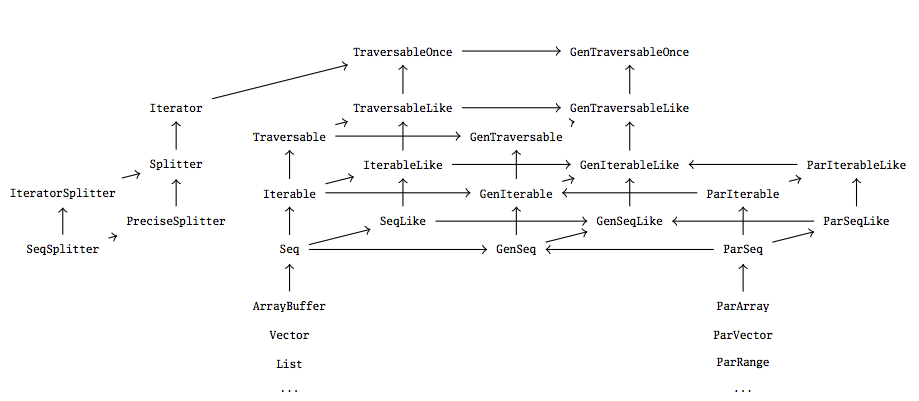
Цель, конечно же, в том, чтобы интегрировать параллельные коллекции с последовательными настолько тесно, насколько это возможно, так, чтобы можно было без дополнительных усилий заменять последовательные коллекции параллельными (и наоборот).
Чтобы можно было получить ссылку на коллекцию, которая может быть либо последовательной, либо параллельной (так, чтобы было возможно “переключаться” между параллельной и последовательной коллекции вызовами par и seq соответственно), у обоих типов коллекций должен быть общий предок. Этим источником “обобщенных” трейтов, как показано выше, являются GenTraversable, GenIterable, GenSeq, GenMap и GenSet, которые не гарантируют того, что элементы будут обрабатываться по-порядку или по-одному. Отсюда наследуются соответствующие последовательные и параллельные трейты; например, ParSeq и Seq являются подтипами общей последовательности GenSeq, а не унаследованы друг от друга.
Более подробное обсуждение иерархии, разделяемой последовательными и параллельными коллекциями, можно найти в техническом отчете. [1]