Martin Odersky, Lex Spoon and Julien Richard-Foy
This article shows how to implement custom collection types on top of the collections framework. It is recommended to first read the article about the architecture of the collections.
What needs to be done if you want to integrate a new collection class, so that it can profit from all predefined operations with the right types? In the next few sections you’ll be walked through three examples that do this, namely capped sequences, sequences of RNA bases and prefix maps implemented with Patricia tries.
Capped sequence
Say you want to create an immutable collection containing at most n elements:
if more elements are added then the first elements are removed.
The first task is to find the supertype of our collection: is it
Seq, Set, Map or just Iterable? In our case, it is tempting
to choose Seq because our collection can contain duplicates and
iteration order is determined by insertion order. However, some
properties of Seq are not satisfied:
(xs ++ ys).size == xs.size + ys.size
Consequently, the only sensible choice as a base collection type
is collection.immutable.Iterable.
First version of Capped class
import scala.collection._
class Capped1[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A] { self =>
def this(capacity: Int) =
this(capacity, length = 0, offset = 0, elems = Array.ofDim(capacity))
def appended[B >: A](elem: B): Capped1[B] = {
val newElems = Array.ofDim[Any](capacity)
Array.copy(elems, 0, newElems, 0, capacity)
val (newOffset, newLength) =
if (length == capacity) {
newElems(offset) = elem
((offset + 1) % capacity, length)
} else {
newElems(length) = elem
(offset, length + 1)
}
new Capped1[B](capacity, newLength, newOffset, newElems)
}
@`inline` def :+ [B >: A](elem: B): Capped1[B] = appended(elem)
def apply(i: Int): A = elems((i + offset) % capacity).asInstanceOf[A]
def iterator: Iterator[A] = new AbstractIterator[A] {
private var current = 0
def hasNext = current < self.length
def next(): A = {
val elem = self(current)
current += 1
elem
}
}
override def className = "Capped1"
}
import scala.collection.*
class Capped1[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A]:
self =>
def this(capacity: Int) =
this(capacity, length = 0, offset = 0, elems = Array.ofDim(capacity))
def appended[B >: A](elem: B): Capped1[B] =
val newElems = Array.ofDim[Any](capacity)
Array.copy(elems, 0, newElems, 0, capacity)
val (newOffset, newLength) =
if length == capacity then
newElems(offset) = elem
((offset + 1) % capacity, length)
else
newElems(length) = elem
(offset, length + 1)
Capped1[B](capacity, newLength, newOffset, newElems)
end appended
inline def :+ [B >: A](elem: B): Capped1[B] = appended(elem)
def apply(i: Int): A = elems((i + offset) % capacity).asInstanceOf[A]
def iterator: Iterator[A] = new AbstractIterator[A]:
private var current = 0
def hasNext = current < self.length
def next(): A =
val elem = self(current)
current += 1
elem
end iterator
override def className = "Capped1"
end Capped1
The above listing presents the first version of our capped collection
implementation. It will be refined later. The class Capped1 has a
private constructor that takes the collection capacity, length,
offset (first element index) and the underlying array as parameters.
The public constructor takes only the capacity of the collection. It
sets the length and offset to 0, and uses an empty array of elements.
The appended method defines how elements can be appended to a given
Capped1 collection: it creates a new underlying array of elements,
copies the current elements and adds the new element. As long as the
number of elements does not exceed the capacity, the new element
is appended after the previous elements. However, as soon as the
maximal capacity has been reached, the new element replaces the first
element of the collection (at offset index).
The apply method implements indexed access: it translates the given
index into its corresponding index in the underlying array by adding
the offset.
These two methods, appended and apply, implement the specific
behavior of the Capped1 collection type. In addition to them, we have
to implement iterator to make the generic collection operations
(such as foldLeft, count, etc.) work on Capped1 collections.
Here we implement it by using indexed access.
Last, we override className to return the name of the collection,
“Capped1”. This name is used by the toString operation.
Here are some interactions with the Capped1 collection:
scala> val c0 = new Capped1(capacity = 4)
val c0: Capped1[Nothing] = Capped1()
scala> val c1 = c0 :+ 1 :+ 2 :+ 3
val c1: Capped1[Int] = Capped1(1, 2, 3)
scala> c1.length
val res2: Int = 3
scala> c1.lastOption
val res3: Option[Int] = Some(3)
scala> val c2 = c1 :+ 4 :+ 5 :+ 6
val c2: Capped1[Int] = Capped1(3, 4, 5, 6)
scala> val c3 = c2.take(3)
val c3: collection.immutable.Iterable[Int] = List(3, 4, 5)
You can see that if we try to grow the collection with more than four
elements, the first elements are dropped (see res4). The operations
behave as expected except for the last one: after calling take we
get back a List instead of the expected Capped1 collection. This
is because all that was done in class
Capped1 was making Capped1 extend
immutable.Iterable. This class has a take method
that returns an immutable.Iterable, and that’s implemented in terms of
immutable.Iterable’s default implementation, List. So, that’s what
you were seeing on the last line of the previous interaction.
Now that you understand why things are the way they are, the next
question should be what needs to be done to change them? One way to do
this would be to override the take method in class Capped1, maybe like
this:
def take(count: Int): Capped1 = …
This would do the job for take. But what about drop, or filter, or
init? In fact there are over fifty methods on collections that return
again a collection. For consistency, all of these would have to be
overridden. This looks less and less like an attractive
option. Fortunately, there is a much easier way to achieve the same
effect, as shown in the next section.
Second version of Capped class
import scala.collection._
class Capped2[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A]
with IterableOps[A, Capped2, Capped2[A]] { self =>
def this(capacity: Int) = // as before
def appended[B >: A](elem: B): Capped2[B] = // as before
@`inline` def :+ [B >: A](elem: B): Capped2[B] = // as before
def apply(i: Int): A = // as before
def iterator: Iterator[A] = // as before
override def className = "Capped2"
override val iterableFactory: IterableFactory[Capped2] = new Capped2Factory(capacity)
override protected def fromSpecific(coll: IterableOnce[A]): Capped2[A] = iterableFactory.from(coll)
override protected def newSpecificBuilder: mutable.Builder[A, Capped2[A]] = iterableFactory.newBuilder
override def empty: Capped2[A] = iterableFactory.empty
}
class Capped2Factory(capacity: Int) extends IterableFactory[Capped2] {
def from[A](source: IterableOnce[A]): Capped2[A] =
(newBuilder[A] ++= source).result()
def empty[A]: Capped2[A] = new Capped2[A](capacity)
def newBuilder[A]: mutable.Builder[A, Capped2[A]] =
new mutable.ImmutableBuilder[A, Capped2[A]](empty) {
def addOne(elem: A): this.type = { elems = elems :+ elem; this }
}
}
class Capped2[A] private(val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A],
IterableOps[A, Capped2, Capped2[A]]:
self =>
def this(capacity: Int) = // as before
def appended[B >: A](elem: B): Capped2[B] = // as before
inline def :+[B >: A](elem: B): Capped2[B] = // as before
def apply(i: Int): A = // as before
def iterator: Iterator[A] = // as before
override def className = "Capped2"
override val iterableFactory: IterableFactory[Capped2] = Capped2Factory(capacity)
override protected def fromSpecific(coll: IterableOnce[A]): Capped2[A] = iterableFactory.from(coll)
override protected def newSpecificBuilder: mutable.Builder[A, Capped2[A]] = iterableFactory.newBuilder
override def empty: Capped2[A] = iterableFactory.empty
end Capped2
class Capped2Factory(capacity: Int) extends IterableFactory[Capped2]:
def from[A](source: IterableOnce[A]): Capped2[A] =
(newBuilder[A] ++= source).result()
def empty[A]: Capped2[A] = Capped2[A](capacity)
def newBuilder[A]: mutable.Builder[A, Capped2[A]] =
new mutable.ImmutableBuilder[A, Capped2[A]](empty):
def addOne(elem: A): this.type =
elems = elems :+ elem; this
end Capped2Factory
The Capped class needs to inherit not only from Iterable, but also
from its implementation trait IterableOps. This is shown in the
above listing of class Capped2. The new implementation differs
from the previous one in only two aspects. First, class Capped2
now also extends IterableOps[A, Capped2, Capped2[A]]. Second,
its iterableFactory member is overridden to return an
IterableFactory[Capped2]. As explained in the
previous sections, the IterableOps trait implements all concrete
methods of Iterable in a generic way. For instance, the
return type of methods like take, drop, filter or init
is the third type parameter passed to class IterableOps, i.e.,
in class Capped2, it is Capped2[A]. Similarly, the return
type of methods like map, flatMap or concat is defined
by the second type parameter passed to class IterableOps,
i.e., in class Capped2, it is Capped2 itself.
Operations returning Capped2[A] collections are implemented in IterableOps
in terms of the fromSpecific and newSpecificBuilder operations. The
immutable.Iterable[A] parent class implements the fromSpecific and
newSpecificBuilder such that they only return immutable.Iterable[A]
collections instead of the expected Capped2[A] collections. Consequently,
we override the fromSpecific and newSpecificBuilder operations to
make them return a Capped2[A] collection. Another inherited operation
returning a too general type is empty. We override it to return a
Capped2[A] collection too. All these overrides simply forward to the
collection factory referred to by the iterableFactory member, whose value
is an instance of class Capped2Factory.
The Capped2Factory class provides convenient factory methods to build
collections. Eventually, these methods delegate to the empty operation,
which builds an empty Capped2 instance, and newBuilder, which uses the
appended operation to grow a Capped2 collection.
With the refined implementation of the Capped2 class,
the transformation operations work now as expected, and the
Capped2Factory class provides seamless conversions from other collections:
scala> object Capped extends Capped2Factory(capacity = 4)
defined object Capped
scala> Capped(1, 2, 3)
val res0: Capped2[Int] = Capped2(1, 2, 3)
scala> res0.take(2)
val res1: Capped2[Int] = Capped2(1, 2)
scala> res0.filter(x => x % 2 == 1)
val res2: Capped2[Int] = Capped2(1, 3)
scala> res0.map(x => x * x)
val res3: Capped2[Int] = Capped2(1, 4, 9)
scala> List(1, 2, 3, 4, 5).to(Capped)
val res4: Capped2[Int] = Capped2(2, 3, 4, 5)
This implementation now behaves correctly, but we can still improve a few things:
- since our collection is strict, we can take advantage of the better performance offered by strict implementations of transformation operations,
- since our
fromSpecific,newSpecificBuilderandemptyoperation just forward to theiterableFactorymember, we can use theIterableFactoryDefaultstrait that provides such implementations.
Final version of Capped class
import scala.collection._
final class Capped[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A]
with IterableOps[A, Capped, Capped[A]]
with IterableFactoryDefaults[A, Capped]
with StrictOptimizedIterableOps[A, Capped, Capped[A]] { self =>
def this(capacity: Int) =
this(capacity, length = 0, offset = 0, elems = Array.ofDim(capacity))
def appended[B >: A](elem: B): Capped[B] = {
val newElems = Array.ofDim[Any](capacity)
Array.copy(elems, 0, newElems, 0, capacity)
val (newOffset, newLength) =
if (length == capacity) {
newElems(offset) = elem
((offset + 1) % capacity, length)
} else {
newElems(length) = elem
(offset, length + 1)
}
new Capped[B](capacity, newLength, newOffset, newElems)
}
@`inline` def :+ [B >: A](elem: B): Capped[B] = appended(elem)
def apply(i: Int): A = elems((i + offset) % capacity).asInstanceOf[A]
def iterator: Iterator[A] = view.iterator
override def view: IndexedSeqView[A] = new IndexedSeqView[A] {
def length: Int = self.length
def apply(i: Int): A = self(i)
}
override def knownSize: Int = length
override def className = "Capped"
override val iterableFactory: IterableFactory[Capped] = new CappedFactory(capacity)
}
class CappedFactory(capacity: Int) extends IterableFactory[Capped] {
def from[A](source: IterableOnce[A]): Capped[A] =
source match {
case capped: Capped[A] if capped.capacity == capacity => capped
case _ => (newBuilder[A] ++= source).result()
}
def empty[A]: Capped[A] = new Capped[A](capacity)
def newBuilder[A]: mutable.Builder[A, Capped[A]] =
new mutable.ImmutableBuilder[A, Capped[A]](empty) {
def addOne(elem: A): this.type = { elems = elems :+ elem; this }
}
}
import scala.collection.*
final class Capped[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A],
IterableOps[A, Capped, Capped[A]],
IterableFactoryDefaults[A, Capped],
StrictOptimizedIterableOps[A, Capped, Capped[A]]:
self =>
def this(capacity: Int) =
this(capacity, length = 0, offset = 0, elems = Array.ofDim(capacity))
def appended[B >: A](elem: B): Capped[B] =
val newElems = Array.ofDim[Any](capacity)
Array.copy(elems, 0, newElems, 0, capacity)
val (newOffset, newLength) =
if length == capacity then
newElems(offset) = elem
((offset + 1) % capacity, length)
else
newElems(length) = elem
(offset, length + 1)
Capped[B](capacity, newLength, newOffset, newElems)
end appended
inline def :+ [B >: A](elem: B): Capped[B] = appended(elem)
def apply(i: Int): A = elems((i + offset) % capacity).asInstanceOf[A]
def iterator: Iterator[A] = view.iterator
override def view: IndexedSeqView[A] = new IndexedSeqView[A]:
def length: Int = self.length
def apply(i: Int): A = self(i)
override def knownSize: Int = length
override def className = "Capped"
override val iterableFactory: IterableFactory[Capped] = new CappedFactory(capacity)
end Capped
class CappedFactory(capacity: Int) extends IterableFactory[Capped]:
def from[A](source: IterableOnce[A]): Capped[A] =
source match
case capped: Capped[?] if capped.capacity == capacity => capped.asInstanceOf[Capped[A]]
case _ => (newBuilder[A] ++= source).result()
def empty[A]: Capped[A] = Capped[A](capacity)
def newBuilder[A]: mutable.Builder[A, Capped[A]] =
new mutable.ImmutableBuilder[A, Capped[A]](empty):
def addOne(elem: A): this.type = { elems = elems :+ elem; this }
end CappedFactory
That is it. The final Capped class:
- extends the
StrictOptimizedIterableOpstrait, which overrides all transformation operations to take advantage of strict builders, - extends the
IterableFactoryDefaultstrait, which overrides thefromSpecific,newSpecificBuilderandemptyoperations to forward to theiterableFactory, - overrides a few operations for performance: the
viewnow uses indexed access, and theiteratordelegates to the view. TheknownSizeoperation is also overridden because the size is always known.
Its implementation requires a little bit of protocol. In essence, you
have to inherit from the Ops template trait in addition to just
inheriting from a collection type, override the iterableFactory
member to return a more specific factory, and finally implement abstract
methods (such as iterator in our case), if any.
RNA sequences
To start with the second example, say you want to create a new immutable sequence type for RNA strands. These are sequences of bases A (adenine), U (uracil), G (guanine), and C (cytosine). The definitions for bases are set up as shown in the listing of RNA bases below:
abstract class Base
case object A extends Base
case object U extends Base
case object G extends Base
case object C extends Base
object Base {
val fromInt: Int => Base = Array(A, U, G, C)
val toInt: Base => Int = Map(A -> 0, U -> 1, G -> 2, C -> 3)
}
Every base is defined as a case object that inherits from a common
abstract class Base. The Base class has a companion object that
defines two functions that map between bases and the integers 0 to 3.
You can see in the above example two different ways to use collections
to implement these functions. The toInt function is implemented as a
Map from Base values to integers. The reverse function, fromInt, is
implemented as an array. This makes use of the fact that both maps and
arrays are functions because they inherit from the Function1 trait.
enum Base:
case A, U, G, C
object Base:
val fromInt: Int => Base = values
val toInt: Base => Int = _.ordinal
Every base is defined as a case of the Base enum. Base has a companion object
that defines two functions that map between bases and the integers 0 to 3.
The toInt function is implemented by delegating to the ordinal method defined on Base,
which is automatically defined because Base is an enum. Each enum case will have a unique ordinal value.
The reverse function, fromInt, is implemented as an array. This makes use of the fact that
arrays are functions because they inherit from the Function1 trait.
The next task is to define a class for strands of RNA. Conceptually, a
strand of RNA is simply a Seq[Base]. However, RNA strands can get
quite long, so it makes sense to invest some work in a compact
representation. Because there are only four bases, a base can be
identified with two bits, and you can therefore store sixteen bases as
two-bit values in an integer. The idea, then, is to construct a
specialized subclass of Seq[Base], which uses this packed
representation.
First version of RNA strands class
import collection.mutable
import collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA1 private (
val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base]
with IndexedSeqOps[Base, IndexedSeq, RNA1] {
import RNA1._
def apply(idx: Int): Base = {
if (idx < 0 || length <= idx)
throw new IndexOutOfBoundsException
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
}
override protected def fromSpecific(coll: IterableOnce[Base]): RNA1 =
fromSeq(coll.iterator.toSeq)
override protected def newSpecificBuilder: mutable.Builder[Base, RNA1] =
iterableFactory.newBuilder[Base].mapResult(fromSeq)
override def empty: RNA1 = fromSeq(Seq.empty)
override def className = "RNA1"
}
object RNA1 {
// Number of bits necessary to represent group
private val S = 2
// Number of groups that fit in an Int
private val N = 32 / S
// Bitmask to isolate a group
private val M = (1 << S) - 1
def fromSeq(buf: collection.Seq[Base]): RNA1 = {
val groups = new Array[Int]((buf.length + N - 1) / N)
for (i <- 0 until buf.length)
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA1(groups, buf.length)
}
def apply(bases: Base*) = fromSeq(bases)
}
import collection.mutable
import collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA1 private
( val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base],
IndexedSeqOps[Base, IndexedSeq, RNA1]:
import RNA1.*
def apply(idx: Int): Base =
if idx < 0 || length <= idx then
throw IndexOutOfBoundsException()
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
override protected def fromSpecific(coll: IterableOnce[Base]): RNA1 =
fromSeq(coll.iterator.toSeq)
override protected def newSpecificBuilder: mutable.Builder[Base, RNA1] =
iterableFactory.newBuilder[Base].mapResult(fromSeq)
override def empty: RNA1 = fromSeq(Seq.empty)
override def className = "RNA1"
end RNA1
object RNA1:
// Number of bits necessary to represent group
private val S = 2
// Number of groups that fit in an Int
private val N = 32 / S
// Bitmask to isolate a group
private val M = (1 << S) - 1
def fromSeq(buf: collection.Seq[Base]): RNA1 =
val groups = new Array[Int]((buf.length + N - 1) / N)
for i <- 0 until buf.length do
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA1(groups, buf.length)
def apply(bases: Base*) = fromSeq(bases)
end RNA1
The RNA strands class listing above
presents the first version of this
class. The class RNA1 has a constructor that
takes an array of Ints as its first argument. This array contains the
packed RNA data, with sixteen bases in each element, except for the
last array element, which might be partially filled. The second
argument, length, specifies the total number of bases on the array
(and in the sequence). Class RNA1 extends IndexedSeq[Base] and
IndexedSeqOps[Base, IndexedSeq, RNA1]. These traits define the following
abstract methods:
length, automatically implemented by defining a parametric field of the same name,apply(indexing method), implemented by first extracting an integer value from thegroupsarray, then extracting the correct two-bit number from that integer using right shift (>>) and mask (&). The private constantsS,N, andMcome from theRNA1companion object.Sspecifies the size of each packet (i.e., two);Nspecifies the number of two-bit packets per integer; andMis a bit mask that isolates the lowestSbits in a word.
We also override the following members used by transformation operations
such as filter and take:
fromSpecific, implemented by thefromSeqmethod of theRNA1companion object,newSpecificBuilder, implemented by using the defaultIndexedSeqbuilder and transforming its result into anRNA1with themapResultmethod.
Note that the constructor of class RNA1 is private. This means that
clients cannot create RNA1 sequences by calling new, which makes
sense, because it hides the representation of RNA1 sequences in terms
of packed arrays from the user. If clients cannot see what the
representation details of RNA sequences are, it becomes possible to
change these representation details at any point in the future without
affecting client code. In other words, this design achieves a good
decoupling of the interface of RNA sequences and its
implementation. However, if constructing an RNA sequence with new is
impossible, there must be some other way to create new RNA sequences,
else the whole class would be rather useless. In fact there are two
alternatives for RNA sequence creation, both provided by the RNA1
companion object. The first way is method fromSeq, which converts a
given sequence of bases (i.e., a value of type Seq[Base]) into an
instance of class RNA1. The fromSeq method does this by packing all
the bases contained in its argument sequence into an array, then
calling RNA1’s private constructor with that array and the length of
the original sequence as arguments. This makes use of the fact that a
private constructor of a class is visible in the class’s companion
object.
The second way to create an RNA1 value is provided by the apply method
in the RNA1 object. It takes a variable number of Base arguments and
simply forwards them as a sequence to fromSeq. Here are the two
creation schemes in action:
scala> val xs = List(A, G, U, A)
val xs: List[Base] = List(A, G, U, A)
scala> RNA1.fromSeq(xs)
val res1: RNA1 = RNA1(A, G, U, A)
scala> val rna1 = RNA1(A, U, G, G, C)
val rna1: RNA1 = RNA1(A, U, G, G, C)
Also note that the type parameters of the IndexedSeqOps trait that
we inherit from are: Base, IndexedSeq and RNA1. The first one
stands for the type of elements, the second one stands for the
type constructor used by transformation operations that return
a collection with a different type of elements, and the third one
stands for the type used by transformation operations that return
a collection with the same type of elements. In our case, it is
worth noting that the second one is IndexedSeq whereas the
third one is RNA1. This means that operations like map or
flatMap return an IndexedSeq, whereas operations like take or
filter return an RNA1.
Here is an example showing the usage of take and filter:
scala> val rna1_2 = rna1.take(3)
val rna1_2: RNA1 = RNA1(A, U, G)
scala> val rna1_3 = rna1.filter(_ != U)
val rna1_3: RNA1 = RNA1(A, G, G, C)
Dealing with map and friends
However, transformation operations that return a collection with a
different element type always return an IndexedSeq.
How should these
methods be adapted to RNA strands? The desired behavior would be to get
back an RNA strand when mapping bases to bases or appending two RNA strands
with ++:
scala> val rna = RNA(A, U, G, G, C)
val rna: RNA = RNA(A, U, G, G, C)
scala> rna.map { case A => U case b => b }
val res7: RNA = RNA(U, U, G, G, C)
scala> rna ++ rna
val res8: RNA = RNA(A, U, G, G, C, A, U, G, G, C)
On the other hand, mapping bases to some other type over an RNA strand
cannot yield another RNA strand because the new elements have the
wrong type. It has to yield a sequence instead. In the same vein
appending elements that are not of type Base to an RNA strand can
yield a general sequence, but it cannot yield another RNA strand.
scala> rna.map(Base.toInt)
val res2: IndexedSeq[Int] = Vector(0, 1, 2, 2, 3)
scala> rna ++ List("missing", "data")
val res3: IndexedSeq[java.lang.Object] =
Vector(A, U, G, G, C, missing, data)
This is what you’d expect in the ideal case. But this is not what the
RNA1 class provides. In fact, all
examples will return instances of Vector, not just the last two. If you run
the first three commands above with instances of this class you obtain:
scala> val rna1 = RNA1(A, U, G, G, C)
val rna1: RNA1 = RNA1(A, U, G, G, C)
scala> rna1.map { case A => U case b => b }
val res0: IndexedSeq[Base] = Vector(U, U, G, G, C)
scala> rna1 ++ rna1
val res1: IndexedSeq[Base] = Vector(A, U, G, G, C, A, U, G, G, C)
So the result of map and ++ is never an RNA strand, even if the
element type of the generated collection is Base. To see how to do
better, it pays to have a close look at the signature of the map
method (or of ++, which has a similar signature). The map method is
originally defined in class scala.collection.IterableOps with the
following signature:
def map[B](f: A => B): CC[B]
Here A is the type of elements of the collection, and CC is the type
constructor passed as a second parameter to the IterableOps trait.
In our RNA1 implementation, this CC type constructor is IndexedSeq,
this is why we always get a Vector as a result.
Second version of RNA strands class
import scala.collection.{ View, mutable }
import scala.collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA2 private (val groups: Array[Int], val length: Int)
extends IndexedSeq[Base] with IndexedSeqOps[Base, IndexedSeq, RNA2] {
import RNA2._
def apply(idx: Int): Base = // as before
override protected def fromSpecific(coll: IterableOnce[Base]): RNA2 = // as before
override protected def newSpecificBuilder: mutable.Builder[Base, RNA2] = // as before
override def empty: RNA2 = // as before
override def className = "RNA2"
// Overloading of `appended`, `prepended`, `appendedAll`,
// `prependedAll`, `map`, `flatMap` and `concat` to return an `RNA2`
// when possible
def concat(suffix: IterableOnce[Base]): RNA2 =
fromSpecific(iterator ++ suffix.iterator)
// symbolic alias for `concat`
@inline final def ++ (suffix: IterableOnce[Base]): RNA2 = concat(suffix)
def appended(base: Base): RNA2 =
fromSpecific(new View.Appended(this, base))
def appendedAll(suffix: IterableOnce[Base]): RNA2 =
concat(suffix)
def prepended(base: Base): RNA2 =
fromSpecific(new View.Prepended(base, this))
def prependedAll(prefix: IterableOnce[Base]): RNA2 =
fromSpecific(prefix.iterator ++ iterator)
def map(f: Base => Base): RNA2 =
fromSpecific(new View.Map(this, f))
def flatMap(f: Base => IterableOnce[Base]): RNA2 =
fromSpecific(new View.FlatMap(this, f))
}
import scala.collection.{ View, mutable }
import scala.collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA2 private (val groups: Array[Int], val length: Int)
extends IndexedSeq[Base], IndexedSeqOps[Base, IndexedSeq, RNA2]:
import RNA2.*
def apply(idx: Int): Base = // as before
override protected def fromSpecific(coll: IterableOnce[Base]): RNA2 = // as before
override protected def newSpecificBuilder: mutable.Builder[Base, RNA2] = // as before
override def empty: RNA2 = // as before
override def className = "RNA2"
// Overloading of `appended`, `prepended`, `appendedAll`,
// `prependedAll`, `map`, `flatMap` and `concat` to return an `RNA2`
// when possible
def concat(suffix: IterableOnce[Base]): RNA2 =
fromSpecific(iterator ++ suffix.iterator)
// symbolic alias for `concat`
inline final def ++ (suffix: IterableOnce[Base]): RNA2 = concat(suffix)
def appended(base: Base): RNA2 =
fromSpecific(View.Appended(this, base))
def appendedAll(suffix: IterableOnce[Base]): RNA2 =
concat(suffix)
def prepended(base: Base): RNA2 =
fromSpecific(View.Prepended(base, this))
def prependedAll(prefix: IterableOnce[Base]): RNA2 =
fromSpecific(prefix.iterator ++ iterator)
def map(f: Base => Base): RNA2 =
fromSpecific(View.Map(this, f))
def flatMap(f: Base => IterableOnce[Base]): RNA2 =
fromSpecific(View.FlatMap(this, f))
end RNA2
To address this shortcoming, you need to overload the methods that
return an IndexedSeq[B] for the case where B is known to be Base,
to return an RNA2 instead.
Compared to class RNA1
we added overloads for methods concat, appended, appendedAll, prepended,
prependedAll, map and flatMap.
This implementation now behaves correctly, but we can still improve a few things. Since our
collection is strict, we could take advantage of the better performance offered by strict builders
in transformation operations.
Also, if we try to convert an Iterable[Base] into an RNA2 it fails:
scala> val bases: Iterable[Base] = List(A, U, C, C)
val bases: Iterable[Base] = List(A, U, C, C)
scala> bases.to(RNA2)
^
error: type mismatch;
found : RNA2.type
required: scala.collection.Factory[Base,?]
scala> val bases: Iterable[Base] = List(A, U, C, C)
val bases: Iterable[Base] = List(A, U, C, C)
scala> bases.to(RNA2)
-- [E007] Type Mismatch Error: -------------------------------------------------
1 |bases.to(RNA2)
| ^^^^
| Found: RNA2.type
| Required: scala.collection.Factory[Base, Any]
|
| longer explanation available when compiling with `-explain`
Final version of RNA strands class
import scala.collection.{ AbstractIterator, SpecificIterableFactory, StrictOptimizedSeqOps, View, mutable }
import scala.collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA private (
val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base]
with IndexedSeqOps[Base, IndexedSeq, RNA]
with StrictOptimizedSeqOps[Base, IndexedSeq, RNA] { rna =>
import RNA._
// Mandatory implementation of `apply` in `IndexedSeqOps`
def apply(idx: Int): Base = {
if (idx < 0 || length <= idx)
throw new IndexOutOfBoundsException
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
}
// Mandatory overrides of `fromSpecific`, `newSpecificBuilder`,
// and `empty`, from `IterableOps`
override protected def fromSpecific(coll: IterableOnce[Base]): RNA =
RNA.fromSpecific(coll)
override protected def newSpecificBuilder: mutable.Builder[Base, RNA] =
RNA.newBuilder
override def empty: RNA = RNA.empty
// Overloading of `appended`, `prepended`, `appendedAll`, `prependedAll`,
// `map`, `flatMap` and `concat` to return an `RNA` when possible
def concat(suffix: IterableOnce[Base]): RNA =
strictOptimizedConcat(suffix, newSpecificBuilder)
@inline final def ++ (suffix: IterableOnce[Base]): RNA = concat(suffix)
def appended(base: Base): RNA =
(newSpecificBuilder ++= this += base).result()
def appendedAll(suffix: Iterable[Base]): RNA =
strictOptimizedConcat(suffix, newSpecificBuilder)
def prepended(base: Base): RNA =
(newSpecificBuilder += base ++= this).result()
def prependedAll(prefix: Iterable[Base]): RNA =
(newSpecificBuilder ++= prefix ++= this).result()
def map(f: Base => Base): RNA =
strictOptimizedMap(newSpecificBuilder, f)
def flatMap(f: Base => IterableOnce[Base]): RNA =
strictOptimizedFlatMap(newSpecificBuilder, f)
// Optional re-implementation of iterator,
// to make it more efficient.
override def iterator: Iterator[Base] = new AbstractIterator[Base] {
private var i = 0
private var b = 0
def hasNext: Boolean = i < rna.length
def next(): Base = {
b = if (i % N == 0) groups(i / N) else b >>> S
i += 1
Base.fromInt(b & M)
}
}
override def className = "RNA"
}
object RNA extends SpecificIterableFactory[Base, RNA] {
private val S = 2 // number of bits in group
private val M = (1 << S) - 1 // bitmask to isolate a group
private val N = 32 / S // number of groups in an Int
def fromSeq(buf: collection.Seq[Base]): RNA = {
val groups = new Array[Int]((buf.length + N - 1) / N)
for (i <- 0 until buf.length)
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA(groups, buf.length)
}
// Mandatory factory methods: `empty`, `newBuilder`
// and `fromSpecific`
def empty: RNA = fromSeq(Seq.empty)
def newBuilder: mutable.Builder[Base, RNA] =
mutable.ArrayBuffer.newBuilder[Base].mapResult(fromSeq)
def fromSpecific(it: IterableOnce[Base]): RNA = it match {
case seq: collection.Seq[Base] => fromSeq(seq)
case _ => fromSeq(mutable.ArrayBuffer.from(it))
}
}
import scala.collection.{ AbstractIterator, SpecificIterableFactory, StrictOptimizedSeqOps, View, mutable }
import scala.collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA private
( val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base],
IndexedSeqOps[Base, IndexedSeq, RNA],
StrictOptimizedSeqOps[Base, IndexedSeq, RNA]:
rna =>
import RNA.*
// Mandatory implementation of `apply` in `IndexedSeqOps`
def apply(idx: Int): Base =
if idx < 0 || length <= idx then
throw new IndexOutOfBoundsException
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
// Mandatory overrides of `fromSpecific`, `newSpecificBuilder`,
// and `empty`, from `IterableOps`
override protected def fromSpecific(coll: IterableOnce[Base]): RNA =
RNA.fromSpecific(coll)
override protected def newSpecificBuilder: mutable.Builder[Base, RNA] =
RNA.newBuilder
override def empty: RNA = RNA.empty
// Overloading of `appended`, `prepended`, `appendedAll`, `prependedAll`,
// `map`, `flatMap` and `concat` to return an `RNA` when possible
def concat(suffix: IterableOnce[Base]): RNA =
strictOptimizedConcat(suffix, newSpecificBuilder)
inline final def ++ (suffix: IterableOnce[Base]): RNA = concat(suffix)
def appended(base: Base): RNA =
(newSpecificBuilder ++= this += base).result()
def appendedAll(suffix: Iterable[Base]): RNA =
strictOptimizedConcat(suffix, newSpecificBuilder)
def prepended(base: Base): RNA =
(newSpecificBuilder += base ++= this).result()
def prependedAll(prefix: Iterable[Base]): RNA =
(newSpecificBuilder ++= prefix ++= this).result()
def map(f: Base => Base): RNA =
strictOptimizedMap(newSpecificBuilder, f)
def flatMap(f: Base => IterableOnce[Base]): RNA =
strictOptimizedFlatMap(newSpecificBuilder, f)
// Optional re-implementation of iterator,
// to make it more efficient.
override def iterator: Iterator[Base] = new AbstractIterator[Base]:
private var i = 0
private var b = 0
def hasNext: Boolean = i < rna.length
def next(): Base =
b = if i % N == 0 then groups(i / N) else b >>> S
i += 1
Base.fromInt(b & M)
override def className = "RNA"
end RNA
object RNA extends SpecificIterableFactory[Base, RNA]:
private val S = 2 // number of bits in group
private val M = (1 << S) - 1 // bitmask to isolate a group
private val N = 32 / S // number of groups in an Int
def fromSeq(buf: collection.Seq[Base]): RNA =
val groups = new Array[Int]((buf.length + N - 1) / N)
for i <- 0 until buf.length do
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA(groups, buf.length)
// Mandatory factory methods: `empty`, `newBuilder`
// and `fromSpecific`
def empty: RNA = fromSeq(Seq.empty)
def newBuilder: mutable.Builder[Base, RNA] =
mutable.ArrayBuffer.newBuilder[Base].mapResult(fromSeq)
def fromSpecific(it: IterableOnce[Base]): RNA = it match
case seq: collection.Seq[Base] => fromSeq(seq)
case _ => fromSeq(mutable.ArrayBuffer.from(it))
end RNA
The final RNA class:
- extends the
StrictOptimizedSeqOpstrait, which overrides all transformation operations to take advantage of strict builders, - uses utility operations provided by the
StrictOptimizedSeqOpstrait such asstrictOptimizedConcatto implement overload of transformation operations that return anRNAcollection, - has a companion object that extends
SpecificIterableFactory[Base, RNA], which makes it possible to use it as a parameter of atocall (to convert any collection of bases to anRNA, e.g.List(U, A, G, C).to(RNA)), - moves the
newSpecificBuilderandfromSpecificimplementations to the companion object.
The discussion so far centered on the minimal amount of definitions
needed to define new sequences with methods that obey certain
types. But in practice you might also want to add new functionality to
your sequences or to override existing methods for better
efficiency. An example of this is the overridden iterator method in
class RNA. iterator is an important method in its own right because it
implements loops over collections. Furthermore, many other collection
methods are implemented in terms of iterator. So it makes sense to
invest some effort optimizing the method’s implementation. The
standard implementation of iterator in IndexedSeq will simply select
every i‘th element of the collection using apply, where i ranges from
0 to the collection’s length minus one. So this standard
implementation selects an array element and unpacks a base from it
once for every element in an RNA strand. The overriding iterator in
class RNA is smarter than that. For every selected array element it
immediately applies the given function to all bases contained in
it. So the effort for array selection and bit unpacking is much
reduced.
Prefix map
As a third example you’ll learn how to integrate a new kind of mutable map
into the collection framework. The idea is to implement a mutable map
with String as the type of keys by a “Patricia trie”. The term
Patricia is in fact an abbreviation for “Practical Algorithm to
Retrieve Information Coded in Alphanumeric” and trie comes from
retrieval (a trie is also called a radix tree or prefix tree).
The idea is to store a set or a map as a tree where subsequent
characters in a search key
uniquely determine a path through the tree. For instance a Patricia trie
storing the strings “abc”, “abd”, “al”, “all” and “xy” would look
like this:
A sample patricia trie:
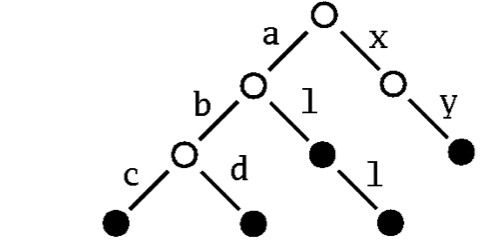
To find the node corresponding to the string “abc” in this trie, simply follow the subtree labeled “a”, proceed from there to the subtree labelled “b”, to finally reach its subtree labelled “c”. If the Patricia trie is used as a map, the value that’s associated with a key is stored in the nodes that can be reached by the key. If it is a set, you simply store a marker saying that the node is present in the set.
Patricia tries support very efficient lookups and updates. Another nice feature is that they support selecting a subcollection by giving a prefix. For instance, in the patricia tree above you can obtain the sub-collection of all keys that start with an “a” simply by following the “a” link from the root of the tree.
Based on these ideas we will now walk you through the implementation
of a map that’s implemented as a Patricia trie. We call the map a
PrefixMap, which means that it provides a method withPrefix that
selects a submap of all keys starting with a given prefix. We’ll first
define a prefix map with the keys shown in the running example:
scala> val m = PrefixMap("abc" -> 0, "abd" -> 1, "al" -> 2,
"all" -> 3, "xy" -> 4)
val m: PrefixMap[Int] = PrefixMap((abc,0), (abd,1), (al,2), (all,3), (xy,4))
Then calling withPrefix on m will yield another prefix map:
scala> m.withPrefix("a")
val res14: PrefixMap[Int] = PrefixMap((bc,0), (bd,1), (l,2), (ll,3))
Patricia trie implementation
import scala.collection._
import scala.collection.mutable.{ GrowableBuilder, Builder }
class PrefixMap[A]
extends mutable.Map[String, A]
with mutable.MapOps[String, A, mutable.Map, PrefixMap[A]]
with StrictOptimizedIterableOps[(String, A), mutable.Iterable, PrefixMap[A]] {
private var suffixes: immutable.Map[Char, PrefixMap[A]] = immutable.Map.empty
private var value: Option[A] = None
def get(s: String): Option[A] =
if (s.isEmpty) value
else suffixes.get(s(0)).flatMap(_.get(s.substring(1)))
def withPrefix(s: String): PrefixMap[A] =
if (s.isEmpty) this
else {
val leading = s(0)
suffixes.get(leading) match {
case None =>
suffixes = suffixes + (leading -> empty)
case _ =>
}
suffixes(leading).withPrefix(s.substring(1))
}
def iterator: Iterator[(String, A)] =
(for (v <- value.iterator) yield ("", v)) ++
(for ((chr, m) <- suffixes.iterator;
(s, v) <- m.iterator) yield (chr +: s, v))
def addOne(kv: (String, A)): this.type = {
withPrefix(kv._1).value = Some(kv._2)
this
}
def subtractOne(s: String): this.type = {
if (s.isEmpty) { val prev = value; value = None; prev }
else suffixes.get(s(0)).flatMap(_.remove(s.substring(1)))
this
}
// Overloading of transformation methods that should return a PrefixMap
def map[B](f: ((String, A)) => (String, B)): PrefixMap[B] =
strictOptimizedMap(PrefixMap.newBuilder, f)
def flatMap[B](f: ((String, A)) => IterableOnce[(String, B)]): PrefixMap[B] =
strictOptimizedFlatMap(PrefixMap.newBuilder, f)
// Override `concat` and `empty` methods to refine their return type
override def concat[B >: A](suffix: IterableOnce[(String, B)]): PrefixMap[B] =
strictOptimizedConcat(suffix, PrefixMap.newBuilder)
override def empty: PrefixMap[A] = new PrefixMap
// Members declared in scala.collection.mutable.Clearable
override def clear(): Unit = suffixes = immutable.Map.empty
// Members declared in scala.collection.IterableOps
override protected def fromSpecific(coll: IterableOnce[(String, A)]): PrefixMap[A] = PrefixMap.from(coll)
override protected def newSpecificBuilder: mutable.Builder[(String, A), PrefixMap[A]] = PrefixMap.newBuilder
override def className = "PrefixMap"
}
object PrefixMap {
def empty[A] = new PrefixMap[A]
def from[A](source: IterableOnce[(String, A)]): PrefixMap[A] =
source match {
case pm: PrefixMap[A] => pm
case _ => (newBuilder ++= source).result()
}
def apply[A](kvs: (String, A)*): PrefixMap[A] = from(kvs)
def newBuilder[A]: mutable.Builder[(String, A), PrefixMap[A]] =
new mutable.GrowableBuilder[(String, A), PrefixMap[A]](empty)
import scala.language.implicitConversions
implicit def toFactory[A](self: this.type): Factory[(String, A), PrefixMap[A]] =
new Factory[(String, A), PrefixMap[A]] {
def fromSpecific(it: IterableOnce[(String, A)]): PrefixMap[A] = self.from(it)
def newBuilder: mutable.Builder[(String, A), PrefixMap[A]] = self.newBuilder
}
}
import scala.collection.*
import scala.collection.mutable.{ GrowableBuilder, Builder }
class PrefixMap[A]
extends mutable.Map[String, A],
mutable.MapOps[String, A, mutable.Map, PrefixMap[A]],
StrictOptimizedIterableOps[(String, A), mutable.Iterable, PrefixMap[A]]:
private var suffixes: immutable.Map[Char, PrefixMap[A]] = immutable.Map.empty
private var value: Option[A] = None
def get(s: String): Option[A] =
if s.isEmpty then value
else suffixes.get(s(0)).flatMap(_.get(s.substring(1)))
def withPrefix(s: String): PrefixMap[A] =
if s.isEmpty then this
else
val leading = s(0)
suffixes.get(leading) match
case None =>
suffixes = suffixes + (leading -> empty)
case _ =>
suffixes(leading).withPrefix(s.substring(1))
def iterator: Iterator[(String, A)] =
(for v <- value.iterator yield ("", v)) ++
(for (chr, m) <- suffixes.iterator
(s, v) <- m.iterator yield (chr +: s, v))
def addOne(kv: (String, A)): this.type =
withPrefix(kv._1).value = Some(kv._2)
this
def subtractOne(s: String): this.type =
if s.isEmpty then { val prev = value; value = None; prev }
else suffixes.get(s(0)).flatMap(_.remove(s.substring(1)))
this
// Overloading of transformation methods that should return a PrefixMap
def map[B](f: ((String, A)) => (String, B)): PrefixMap[B] =
strictOptimizedMap(PrefixMap.newBuilder, f)
def flatMap[B](f: ((String, A)) => IterableOnce[(String, B)]): PrefixMap[B] =
strictOptimizedFlatMap(PrefixMap.newBuilder, f)
// Override `concat` and `empty` methods to refine their return type
override def concat[B >: A](suffix: IterableOnce[(String, B)]): PrefixMap[B] =
strictOptimizedConcat(suffix, PrefixMap.newBuilder)
override def empty: PrefixMap[A] = PrefixMap()
// Members declared in scala.collection.mutable.Clearable
override def clear(): Unit = suffixes = immutable.Map.empty
// Members declared in scala.collection.IterableOps
override protected def fromSpecific(coll: IterableOnce[(String, A)]): PrefixMap[A] = PrefixMap.from(coll)
override protected def newSpecificBuilder: mutable.Builder[(String, A), PrefixMap[A]] = PrefixMap.newBuilder
override def className = "PrefixMap"
end PrefixMap
object PrefixMap:
def empty[A] = new PrefixMap[A]
def from[A](source: IterableOnce[(String, A)]): PrefixMap[A] =
source match
case pm: PrefixMap[A @unchecked] => pm
case _ => (newBuilder ++= source).result()
def apply[A](kvs: (String, A)*): PrefixMap[A] = from(kvs)
def newBuilder[A]: mutable.Builder[(String, A), PrefixMap[A]] =
mutable.GrowableBuilder[(String, A), PrefixMap[A]](empty)
import scala.language.implicitConversions
implicit def toFactory[A](self: this.type): Factory[(String, A), PrefixMap[A]] =
new Factory[(String, A), PrefixMap[A]]:
def fromSpecific(it: IterableOnce[(String, A)]): PrefixMap[A] = self.from(it)
def newBuilder: mutable.Builder[(String, A), PrefixMap[A]] = self.newBuilder
end PrefixMap
The previous listing shows the definition of PrefixMap. The map has
keys of type String and the values are of parametric type A. It extends
mutable.Map[String, A] and mutable.MapOps[String, A, mutable.Map, PrefixMap[A]].
You have seen this pattern already for sequences in the
RNA strand example; then as now inheriting an implementation class
such as MapOps serves to get the right result type for
transformations such as filter.
A prefix map node has two mutable fields: suffixes and value. The
value field contains an optional value that’s associated with the
node. It is initialized to None. The suffixes field contains a map
from characters to PrefixMap values. It is initialized to the empty
map.
You might ask why we picked an immutable map as the implementation
type for suffixes? Would not a mutable map have been more standard,
since PrefixMap as a whole is also mutable? The answer is that
immutable maps that contain only a few elements are very efficient in
both space and execution time. For instance, maps that contain fewer
than 5 elements are represented as a single object. By contrast, the
standard mutable map is a HashMap, which typically occupies around 80
bytes, even if it is empty. So if small collections are common, it’s
better to pick immutable over mutable. In the case of Patricia tries,
we’d expect that most nodes except the ones at the very top of the
tree would contain only a few successors. So storing these successors
in an immutable map is likely to be more efficient.
Now have a look at the first method that needs to be implemented for a
map: get. The algorithm is as follows: To get the value associated
with the empty string in a prefix map, simply select the optional
value stored in the root of the tree (the current map).
Otherwise, if the key string is
not empty, try to select the submap corresponding to the first
character of the string. If that yields a map, follow up by looking up
the remainder of the key string after its first character in that
map. If the selection fails, the key is not stored in the map, so
return with None. The combined selection over an option value opt is
elegantly expressed using opt.flatMap(x => f(x)). When applied to an
optional value that is None, it returns None. Otherwise opt is
Some(x) and the function f is applied to the encapsulated value x,
yielding a new option, which is returned by the flatmap.
The next two methods to implement for a mutable map are addOne and subtractOne.
The subtractOne method is very similar to get, except that before returning
any associated value, the field containing that value is set to
None. The addOne method first calls withPrefix to navigate to the tree
node that needs to be updated, then sets the value field of that node
to the given value. The withPrefix method navigates through the tree,
creating sub-maps as necessary if some prefix of characters is not yet
contained as a path in the tree.
The last abstract method to implement for a mutable map is
iterator. This method needs to produce an iterator that yields all
key/value pairs stored in the map. For any given prefix map this
iterator is composed of the following parts: First, if the map
contains a defined value, Some(x), in the value field at its root,
then ("", x) is the first element returned from the
iterator. Furthermore, the iterator needs to traverse the iterators of
all submaps stored in the suffixes field, but it needs to add a
character in front of every key string returned by those
iterators. More precisely, if m is the submap reached from the root
through a character chr, and (s, v) is an element returned from
m.iterator, then the root’s iterator will return (chr +: s, v)
instead. This logic is implemented quite concisely as a concatenation
of two for expressions in the implementation of the iterator method in
PrefixMap. The first for expression iterates over value.iterator. This
makes use of the fact that Option values define an iterator method
that returns either no element, if the option value is None, or
exactly one element x, if the option value is Some(x).
However, in all these cases, to build the right kind of collection
you need to start with an empty collection of that kind. This is
provided by the empty method, which simply returns a fresh PrefixMap.
We’ll now turn to the companion object PrefixMap. In fact, it is not
strictly necessary to define this companion object, as class PrefixMap
can stand well on its own. The main purpose of object PrefixMap is to
define some convenience factory methods. It also defines an implicit
conversion to Factory for a better interoperability with other
collections. This conversion is triggered when one writes, for instance,
List("foo" -> 3).to(PrefixMap). The to operation takes a Factory
as parameter but the PrefixMap companion object does not extend Factory (and it
can not because a Factory fixes the type of collection elements,
whereas PrefixMap has a polymorphic type of values).
The two convenience methods are empty and apply. The same methods are
present for all other collections in Scala’s collection framework, so
it makes sense to define them here, too. With the two methods, you can
write PrefixMap literals like you do for any other collection:
scala> PrefixMap("hello" -> 5, "hi" -> 2)
val res0: PrefixMap[Int] = PrefixMap(hello -> 5, hi -> 2)
scala> res0 += "foo" -> 3
val res1: res0.type = PrefixMap(hello -> 5, hi -> 2, foo -> 3)
Summary
To summarize, if you want to fully integrate a new collection class into the framework you need to pay attention to the following points:
- Decide whether the collection should be mutable or immutable.
- Pick the right base traits for the collection.
- Inherit from the right implementation trait to implement most collection operations.
- Overload desired operations that do not return, by default, a collection as specific as they could. A complete list of such operations is given as an appendix.
You have now seen how Scala’s collections are built and how you can add new kinds of collections. Because of Scala’s rich support for abstraction, each new collection type has a large number of methods without having to reimplement them all over again.
Acknowledgement
This page contains material adapted from the book Programming in Scala by Odersky, Spoon and Venners. We thank Artima for graciously agreeing to its publication.
Appendix: Methods to overload to support the “same result type” principle
You want to add overloads to specialize transformation operations such that they return a more specific result type. Examples are:
map, onStringOps, when the mapping function returns aChar, should return aString(instead of anIndexedSeq),map, onMap, when the mapping function returns a pair, should return aMap(instead of anIterable),map, onSortedSet, when an implicitOrderingis available for the resulting element type, should return aSortedSet(instead of aSet).
Typically, this happens when the collection fixes some type parameter of its template trait. For instance in
the case of the RNA collection type, we fix the element type to Base, and in the case of the PrefixMap[A]
collection type, we fix the type of keys to String.
The following table lists transformation operations that might return an undesirably wide type. You might want to overload these operations to return a more specific type.
| Collection | Operations |
|---|---|
Iterable |
map, flatMap, collect, scanLeft, scanRight, groupMap, concat, zip, zipAll, unzip |
Seq |
prepended, appended, prependedAll, appendedAll, padTo, patch |
immutable.Seq |
updated |
SortedSet |
map, flatMap, collect, zip |
Map |
map, flatMap, collect, concat |
immutable.Map |
updated, transform |
SortedMap |
map, flatMap, collect, concat |
immutable.SortedMap |
updated |
Appendix: Cross-building custom collections
Since the new internal API of the Scala 2.13 collections is very different from the previous collections API, authors of custom collection types should use separate source directories (per Scala version) to define them.
With sbt you can achieve this by adding the following setting to your project:
// Adds a `src/main/scala-2.13+` source directory for Scala 2.13 and newer
// and a `src/main/scala-2.13-` source directory for Scala version older than 2.13
unmanagedSourceDirectories in Compile += {
val sourceDir = (sourceDirectory in Compile).value
CrossVersion.partialVersion(scalaVersion.value) match {
case Some((2, n)) if n >= 13 => sourceDir / "scala-2.13+"
case _ => sourceDir / "scala-2.13-"
}
}
And then you can define a Scala 2.13 compatible implementation of your collection
in the src/main/scala-2.13+ source directory, and an implementation for the
previous Scala versions in the src/main/scala-2.13- source directory.
You can see how this has been put in practice in scalacheck and scalaz.