像正常的顺序集合库那样,Scala的并行集合库包含了大量的由不同并行集合实现的一致的集合操作。并且像顺序集合库那样,scala的并行集合库通过并行集合“模板”实现了大部分操作,从而防止了代码重复。“模板”只需要定义一次就可以通过不同的并行集合被灵活地继承。
这种方法的好处是大大缓解了维护和可扩展性。对于维护–所有的并行集合通过继承一个有单一实现的并行集合,维护变得更容易和更健壮;bug修复传播到类层次结构,而不需要复制实现。出于同样的原因,整个库变得更易于扩展–新的集合类可以简单地继承大部分的操作。
核心抽象
上述的”模板“特性实现的多数并行操作都是根据两个核心抽象–分割器和组合器。
分割器
Spliter的工作,正如其名,它把一个并行集合分割到了它的元素的非重要分区里面。基本的想法是将集合分割成更小的部分直到他们小到足够在序列上操作。
trait Splitter[T] extends Iterator[T] {
def split: Seq[Splitter[T]]
}
有趣的是,分割器是作为迭代器实现的,这意味着除了分割,他们也被框架用来遍历并行集合(也就是说,他们继承了迭代器的标准方法,如next()和hasNext())。这种“分割迭代器”的独特之处是它的分割方法把自身(迭代器类型的分割器)进一步分割成额外的分割器,这些新的分割器能遍历到整个并行集合的不相交的元素子集。类似于正常的迭代器,分割器在调用分割方法后失效。
一般来说,集合是使用分割器(Splitters)分成大小大致相同的子集。在某些情况下,任意大小的分区是必须的,特别是在并行序列上,PreciseSplitter(精确的分割器)是很有用的,它是继承于Splitter和另外一个实现了精确分割的方法–psplit.
组合器
组合器被认为是一个来自于Scala序列集合库的广义构造器。每一个并行集合都提供一个单独的组合器,同样,每一个序列集合也提供一个构造器。
而对于序列集合,元素可以被增加到一个构造器中去,并且集合可以通过调用结果方法生成,对于并行集合,组合器有一个叫做combine的方法,它调用其他的组合器进行组合并产生包含两个元素的并集的新组合器。当调用combine方法后,这两个组合器都会变成无效的。
trait Combiner[Elem, To] extends Builder[Elem, To] { def combine(other: Combiner[Elem, To]): Combiner[Elem, To] } 这两个类型参数Elem,根据上下文分别表示元素类型和结果集合的类型。
注意:鉴于两个组合器,c1和c2,在c1=c2为真(意味它们是同一个组合器),调用c1.combine(c2)方法总是什么都不做并且简单的返回接收的组合器c1。
层级
Scala的并行集合吸收了很多来自于Scala的(序列)集合库的设计灵感–事实上,它反映了规则地集合框架的相应特征,如下所示。
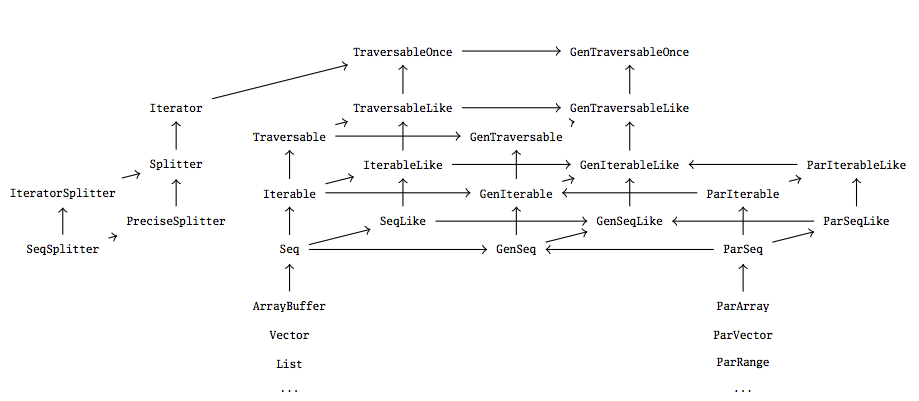
Scala集合的层次和并行集合库
当然我们的目标是尽可能紧密集成并行集合和序列集合,以允许序列集合和并行集合之间的简单替代。
为了能够获得一个序列集合或并行集合的引用(这样可以通过par和seq在并行集合和序列集合之间切换),两种集合类型存在一个共同的超型。这是上面所示的“通用”特征的起源,GenTraversable, GenIterable, GenSeq, GenMap and GenSet,不保证按次序或挨个的遍历。相应的序列或并行特征继承于这些。例如,一个ParSeq和Seq都是一个通用GenSeq的子类型,但是他们之间没有相互公认的继承关系。
更详细的讨论序列集合和并行集合器之间的层次共享,请参见技术报告。[1]
引用