Martin Odersky 和 Lex Spoon 著
本篇详细的介绍了Scala 容器类(collections)框架。通过与 Scala 2.8 的 Collection API 的对比,你会了解到更多框架的内部运作方式,同时你也将学习到如何通过几行代码复用这个容器类框架的功能来定义自己的容器类。
Scala 2.8 容器API 中包含了大量的 容器(collection)操作,这些操作在不同的许多容器类上表现为一致。假设,为每种 Collection 类型都用不同的方法代码实现,那么将导致代码的异常臃肿,很多代码将会仅仅是别处代码的拷贝。随着时间的推移,这些重复的代码也会带来不一致的问题,试想,相同的代码,在某个地方被修改了,而另外的地方却被遗漏了。而新的 容器类(collections)框架的设计原则目标就是尽量的避免重复,在尽可能少的地方定义操作(理想情况下,只在一处定义,当然也会有例外的情况存在)。设计中使用的方法是,在 Collection 模板中实现大部分的操作,这样就可以灵活的从独立的基类和实现中继承。后面的部分,我们会来详细阐述框架的各组成部分:模板(templates)、类(classes)以及trait(译注:类似于java里接口的概念),也会说明他们所支持的构建原则。
Builders
Builder类概要:
package scala.collection.mutable
class Builder[-Elem, +To] {
def +=(elem: Elem): this.type
def result(): To
def clear(): Unit
def mapResult[NewTo](f: To => NewTo): Builder[Elem, NewTo] = ...
}
几乎所有的 Collection 操作都由遍历器(traversals)和构建器 (builders)来完成。Traversal 用可遍历类的foreach方法来实现,而构建新的 容器(collections)是由构建器类的实例来完成。上面的代码就是对这个类的精简描述。
我们用 b += x 来表示为构建器 b 加上元素 x。也可以一次加上多个元素,例如: b += (x, y) 及 b ++= x ,这类似于缓存(buffers)的工作方式(实际上,缓存就是构建器的增强版)。构建器的 result() 方法会返回一个collection。在获取了结果之后,构建器的状态就变成未定义,调用它的 clear() 方法可以把状态重置成空状态。构建器是通用元素类型,它适用于元素,类型,及它所返回的Collection。
通常,一个builder可以使用其他的builder来组合一个容器的元素,但是如果想要把其他builder返回的结果进行转换,例如,转成另一种类型,就需要使用Builder类的mapResult方法。假设,你有一个数组buffer,名叫 buf。一个ArrayBuffer的builder 的 result() 返回它自身。如果想用它去创建一个新的ArrayBuffer的builder,就可以使用 mapResult :
scala> val buf = new ArrayBuffer[Int]
buf: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer()
scala> val bldr = buf mapResult (_.toArray)
bldr: scala.collection.mutable.Builder[Int,Array[Int]]
= ArrayBuffer()
结果值 bldr,是使用 buf 来收集元素的builder。当调用 bldr 的result时,其实是调用的 buf 的result,结果是返回的buf本身。接着这个数组buffer用 _.toArray 映射成了一个数组,结果 bldr 也就成了一个数组的 builder.
分解(factoring out)通用操作
TraversableLike类概述
package scala.collection
class TraversableLike[+Elem, +Repr] {
def newBuilder: Builder[Elem, Repr] // deferred
def foreach[U](f: Elem => U) // deferred
...
def filter(p: Elem => Boolean): Repr = {
val b = newBuilder
foreach { elem => if (p(elem)) b += elem }
b.result
}
}
Collection库重构的主要设计目标是在拥有自然类型的同时又尽可能的共享代码实现。Scala的Collection 遵从“结果类型相同”的原则:只要可能,容器上的转换方法最后都会生成相同类型的Collection。例如,过滤操作对各种Collection类型都应该产生相同类型的实例。在List上应用过滤器应该获得List,在Map上应用过滤器,应该获得Map,如此等等。在下面的章节中,会告诉大家该原则的实现方法。
Scala的 Collection 库通过在 trait 实现中使用通用的构建器(builders)和遍历器(traversals)来避免代码重复、实现“结果类型相同”的原则。这些Trait的名字都有Like后缀。例如:IndexedSeqLike 是 IndexedSeq 的 trait 实现,再如,TraversableLike 是 Traversable 的 trait 实现。和普通的 Collection 只有一个类型参数不同,trait实现有两个类型参数。他们不仅参数化了容器的成员类型,也参数化了 Collection 所代表的类型,就像下面的 Seq[I] 或 List[T]。下面是TraversableLike开头的描述:
trait TraversableLike[+Elem, +Repr] { ... }
类型参数Elem代表Traversable的元素类型,参数Repr代表它自身。Repr上没有限制,甚至,Repr可以是非Traversable子类的实例。这就意味这,非容器子类的类,例如String和Array也可以使用所有容器实现trait中包含的操作。
以过滤器为例,这个操作只在TraversableLike定义了一次,就使得它适用于所有的容器类(collections)。通过查看前面 TraversableLike类的概述中相关的代码描述,我们知道,该trait声明了两个抽象方法,newBuilder 和 foreach,这些抽象方法在具体的collection类中实现。过滤器也是用这两个方法,通过相同的方式来实现的。首先,它用 newBuiler 方法构造一个新的builder,类型为 Repr 的类型。然后,使用 foreach 来遍历当前 collection 中的所有元素。一旦某个元素 x 满足谓词 p (即,p(x)为真),那么就把x加入到builder中。最后,用 builder 的 result 方法返回类型同 Repr 的 collection,里面的元素就是上面收集到的满足条件的所有元素。
容器(collections)上的映射操作就更复杂。例如:如果 f 是一个以一个String类型为参数并返回一个Int类型的函数,xs 是一个 List[String],那么在xs上使用该映射函数 f 应该会返回 List[Int]。同样,如果 ys 是一个 Array[String],那么通过 f 映射,应该返回 Array[Int]。 这里的难点在于,如何实现这样的效果而又不用分别针对 list 和 array 写重复的代码。TraversableLike 类的 newBuilder/foreach 也完成不了这个任务,因为他们需要生成一个完全相同类型的容器(collection)类型,而映射需要的是生成一个相同类型但内部元素类型却不同的容器。
很多情况下,甚至像map的构造函数的结果类型都可能是不那么简单的,因而需要依靠于其他参数类型,比如下面的例子:
scala> import collection.immutable.BitSet
import collection.immutable.BitSet
scala> val bits = BitSet(1, 2, 3)
bits: scala.collection.immutable.BitSet = BitSet(1, 2, 3)
scala> bits map (_ * 2)
res13: scala.collection.immutable.BitSet = BitSet(2, 4, 6)
scala> bits map (_.toFloat)
res14: scala.collection.immutable.Set[Float]
= Set(1.0, 2.0, 3.0)
在一个BitSet上使用倍乘映射 *2,会得到另一个BitSet。然而,如果在相同的BitSet上使用映射函数 (.toFloat) 结果会得到一个 Set[Float]。这样也很合理,因为 BitSet 中只能放整型,而不能存放浮点型。
因此,要提醒大家注意,映射(map)的结果类型是由传进来的方法的类型决定的。如果映射函数中的参数会得到Int类型的值,那么映射的结果就是 BitSet。但如果是其他类型,那么映射的结果就是 Set 类型。后面会让大家了解 Scala 这种灵活的类型适应是如何实现的。
类似 BitSet 的问题不是唯一的,这里还有在map类型上应用map函数的交互式例子:
scala> Map("a" -> 1, "b" -> 2) map { case (x, y) => (y, x) }
res3: scala.collection.immutable.Map[Int,java.lang.String]
= Map(1 -> a, 2 -> b)
scala> Map("a" -> 1, "b" -> 2) map { case (x, y) => y }
res4: scala.collection.immutable.Iterable[Int]
= List(1, 2)
第一个函数用于交换两个键值对。这个函数映射的结果是一个类似的Map,键和值颠倒了。事实上,地一个表达式产生了一个键值颠倒的map类型(在原map可颠倒的情况下)。然而,第二个函数,把键值对映射成一个整型,即成员变成了具体的值。在这种情况下,我们不可能把结果转换成Map类型,因此处理成,把结果转换成Map的一个可遍历的超类,这里是List。
你可能会问,哪为什么不强制让映射都返回相同类型的Collection呢?例如:BitSet上的映射只能接受整型到整型的函数,而Map上的映射只能接受键值对到键值对的函数。但这种约束从面向对象的观点来看是不能接受的,它会破坏里氏替换原则(Liskov substitution principle),即:Map是可遍历类,因此所有在可遍历类上的合法的操作都必然在Map中合法。
Scala通过重载来解决这个问题:Scala中的重载并非简单的复制Java的实现(Java的实现不够灵活),它使用隐式参数所提供的更加系统化的重载方式。
TraversableLike 中映射(map)的实现:
def map[B, That](p: Elem => B)
(implicit bf: CanBuildFrom[B, That, This]): That = {
val b = bf(this)
for (x <- this) b += f(x)
b.result
}
上面的代码展示了TraversableLike如何实现映射的trait。看起来非常类似于TraversableLike类的过滤器的实现。主要的区别在于,过滤器使用TraversableLike类的抽象方法 newBuilder,而映射使用的是Builder工场,它作为CanBuildFrom类型的一个额外的隐式参数传入。
CanBuildFrom trait:
package scala.collection.generic
trait CanBuildFrom[-From, -Elem, +To] {
// 创建一个新的构造器(builder)
def apply(from: From): Builder[Elem, To]
}
上面的代码是 trait CanBuildFrom 的定义,它代表着构建者工场。它有三个参数:Elem是要创建的容器(collection)的元素的类型,To是要构建的容器(collection)的类型,From是该构建器工场适用的类型。通过定义适合的隐式定义的构建器工场,你就可以构建出符合你需要的类型转换行为。以 BitSet 类为例,它的伴生对象包含一个 CanBuildFrom[BitSet, Int, BitSet] 类型的构建器工场。这就意味着,当在一个 BitSet 上执行操作的时候,你可以创建另一个元素类型为整型的 BitSet。如果你需要的类型不同,那么,你还可以使用其他的隐式构建器工场,它们在Set的伴生对象中实现。下面就是一个更通用的构建器,A是通用类型参数:
CanBuildFrom[Set[_], A, Set[A]]
这就意味着,当操作一个任意Set(用现有的类型 Set[] 表述),我们可以再次创建一个 Set,并且无需关心它的元素类型A是什么。给你两个 CanBuildFrom 的隐式实例,你有可以利用 Scala 的隐式解析(implicit resolution)规则去挑选出其中最契合的一个。
所以说,隐式解析(implicit resolution)为类似映射的比较棘手的Collection操作提供了正确的静态类型。但是动态类型又怎么办呢?特别是,假设你有一个List,作为静态类型它有遍历方法,你在它上面使用一些映射(map)方法:
scala> val xs: Iterable[Int] = List(1, 2, 3)
xs: Iterable[Int] = List(1, 2, 3)
scala> val ys = xs map (x => x * x)
ys: Iterable[Int] = List(1, 4, 9)
上述ys的静态类型是可遍历的(Iterable)类型。但是它的动态类型仍然必须是List类型的!此行为是间接被实现的。在CanBuildFrom的apply方法被作为参数传递源容器中。大多数的builder工厂仿制traversables(除建造工厂意外所有的叶子类型(leaf classes))将调用转发到集合的方法genericBuilder。反过来genericBuilder方法调用属于在定义它收集的建设者。所以Scala使用静态隐式解析,以解决map类型的限制问题,以及分派挑选对应于这些约束最佳的动态类型。
集成新容器
如果想要集成一个新的容器(Collection)类,以便受益于在正确类型上预定义的操作,需要做些什么呢?在下面几页中,将通过两个例子来进行演示。
集成序列(Sequence)
RNA(核糖核酸)碱基(译者注:RNA链即很多不同RNA碱基的序列,RNA参考资料:https://zh.wikipedia.org/wiki/RNA):
abstract class Base
case object A extends Base
case object T extends Base
case object G extends Base
case object U extends Base
object Base {
val fromInt: Int => Base = Array(A, T, G, U)
val toInt: Base => Int = Map(A -> 0, T -> 1, G -> 2, U -> 3)
}
假设需要为RNA链建立一个新的序列类型,这些RNA链是由碱基A(腺嘌呤)、T(胸腺嘧啶)、G(鸟嘌呤)、U(尿嘧啶)组成的序列。如上述列出的RNA碱基,很容易建立碱基的定义。
每个碱基都定义为一个具体对象(case object),该对象继承自一个共同的抽象类Base(碱基)。这个Base类具有一个伴生对象(companion object),该伴生对象定义了描述碱基和整数(0到3)之间映射的2个函数。可以从例子中看到,有两种不同的方式来使用容器(Collection)来实现这些函数。toInt函数通过一个从Base值到整数之间的映射(map)来实现。而它的逆函数fromInt则通过数组来实现。以上这些实现方法都基于一个事实,即“映射和数组都是函数”。因为他们都继承自Function1 trait。
下一步任务,便是为RNA链定义一个类。从概念上来看,一个RNA链就是一个简单的Seq[Base]。然而,RNA链可以很长,所以值的去花点时间来简化RNA链的表现形式。因为只有4种碱基,所以每个碱基可以通过2个比特位来区别。因此,在一个integer中,可以保存16个由2位比特标示的碱基。即构造一个Seq[Base]的特殊子类,并使用这种压缩的表示(packed representation)方式。
RNA链类的第一个版本
import collection.IndexedSeqLike
import collection.mutable.{Builder, ArrayBuffer}
import collection.generic.CanBuildFrom
final class RNA1 private (val groups: Array[Int],
val length: Int) extends IndexedSeq[Base] {
import RNA1._
def apply(idx: Int): Base = {
if (idx < 0 || length <= idx)
throw new IndexOutOfBoundsException
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
}
}
object RNA1 {
// 表示一组所需要的比特数
private val S = 2
// 一个Int能够放入的组数
private val N = 32 / S
// 分离组的位掩码(bitmask)
private val M = (1 << S) - 1
def fromSeq(buf: Seq[Base]): RNA1 = {
val groups = new Array[Int]((buf.length + N - 1) / N)
for (i <- 0 until buf.length)
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA1(groups, buf.length)
}
def apply(bases: Base*) = fromSeq(bases)
}
上面的RNA链类呈现出这个类的第一个版本,它将在以后被细化。类RNA1有一个构造函数,这个构造函数将int数组作为第一个参数。而这个数组包含打包压缩后的RNA数据,每个数组元素都有16个碱基,而最后一个元素则只有一部分有数据。第二个参数是长度,指定了数组中(和序列中)碱基的总数。RNA1类扩展了IndexedSeq[Base]。而IndexedSeq来自scala.collection.immutable,IndexedSeq定义了两个抽象方法:length和apply。这方法些需要在具体的子类中实现。类RNA1通过定义一个相同名字的参数字段来自动实现length。同时,通过类RNA1中给出的代码实现了索引方法apply。实质上,apply方法首先从数组中提取出一个整数值,然后再对这个整数中使用右移位(»)和掩码(&)提取出正确的两位比特。私有常数S、N来自RNA1的伴生对象,S指定了每个包的尺寸(也就是2),N指定每个整数的两位比特包的数量,而M则是一个比特掩码,分离出一个字(word)的低S位。
注意,RNA1类的构造函数是一个私有函数。这意味着用户端无法通过调用new函数来创建RNA1序列的实例。这是有意义的,因为这能对用户隐藏RNA1序列包装数组的实现。如果用户端无法看到RNA序列的具体实现,以后任何时候,就可以做到改变RNA序列具体实现的同时,不影响到用户端代码。换句话说,这种设计实现了RNA序列的接口和实现之间解藕。然而,如果无法通过new来创建一个RNA序列,那就必须存在其他方法来创建它,否则整个类就变得毫无用处。事实上,有两种建立RNA序列的替代途径,两者都由RNA1的伴生对象(companion object)提供。第一个途径是fromSeq方法,这个方法将一个给定的碱基序列(也就是一个Seq[Base]类型的值)转换成RNA1类的实例。fromSeq方法将所有其序列参数内的碱基打包进一个数组。然后,将这个数组以及原序列的长度作为参数,调用RNA1的私有构造函数。这利用了一个事实:一个类的私有构造函数对于其伴生对象(companion object)是可见的。
创建RNA1实例的第二种途径由RNA1对象中的apply方法提供。它使用一个可变数量的Base类参数,并简单地将其作为序列指向fromSeq方法。这里是两个创建RNA实例的实际方案。
scala> val xs = List(A, G, T, A)
xs: List[Product with Base] = List(A, G, T, A)
scala> RNA1.fromSeq(xs)
res1: RNA1 = RNA1(A, G, T, A)
scala> val rna1 = RNA1(A, U, G, G, T)
rna1: RNA1 = RNA1(A, U, G, G, T)
控制RNA类型中方法的返回值
这里有一些和RNA1抽象之间更多的交互操作
scala> rna1.length
res2: Int = 5
scala> rna1.last
res3: Base = T
scala> rna1.take(3)
res4: IndexedSeq[Base] = Vector(A, U, G)
前两个返回值正如预期,但最后一个——从rna1中获得前3个元素——的返回值则未必如预期。实际上,我们知道一个IndexedSeq[Base]作为返回值的静态类型而一个Vector作为返回值的动态类型,但我们更想看到一个RNA1的值。但这是无法做到的,因为之前在RNA1类中所做的一切仅仅是让RNA1扩展IndexedSeq。换句话说,IndexedSeq类具有一个take方法,其返回一个IndexedSeq。并且,这个方法是根据 IndexedSeq 的默认是用Vector来实现的。所以,这就是上一个交互中最后一行上所能看到的。
RNA链类的第二个版本
final class RNA2 private (
val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base] with IndexedSeqLike[Base, RNA2] {
import RNA2._
override def newBuilder: Builder[Base, RNA2] =
new ArrayBuffer[Base] mapResult fromSeq
def apply(idx: Int): Base = // as before
}
现在,明白了本质之后,下一个问题便是如何去改变它们。一种途径便是覆写(override)RNA1类中的take方法,可能如下所示:
def take(count: Int): RNA1 = RNA1.fromSeq(super.take(count))
这对take函数有效,但drop、filter或者init又如何呢?事实上,序列(Sequence)中有超过50个方法同样返回序列。为了保持一致,所有这些方法都必须被覆写。这看起来越来越不像一个有吸引力的选择。幸运的是,有一种更简单的途径来达到同样的效果。RNA类不仅需要继承自IndexedSeq类,同时继承自它的实现trait(特性)IndexedSeqLike。如上面的RNA2所示。新的实现在两个方面与之前不同。第一个,RNA2类现在同样扩展自IndexedSeqLike[Base, RNA2]。这个IndexedSeqLike trait(特性)以可扩展的方式实现了所有IndexedSeq的具体方法。比如,如take、drop、filer或init的返回值类型即是传给IndexedSeqLike类的第二个类型参数,也就是说,在RNA2中的是RNA2本身。
为了能够做,IndexedSeqLike将自身建立在newBuilder抽象上,这个抽象能够创建正确类型的builder。IndexedSeqLike trait(特性)的子类必须覆写newBuilder以返回一个它们自身类型的容器。在RNA2类中,newBuilder方法返回一个Builder[Base, RNA2]类型的builder。
为了构造这个builder,首先创建一个ArrayBuffer,其自身就是一个Builder[Base, ArrayBuffer]。然后通过调用其mapResult方法来将这个ArrayBuffer转换为一个RNA2 builder。mapResult方法需要一个从ArrayBuffer到RNA2的转换函数来作为其参数。转换函数仅仅提供RNA2.fromSeq,其将一个任意的碱基序列转换为RNA2值(之前提到过,数组缓冲是一种序列,所以RNA2.fromSeq可对其使用)。
如果忘记声明newBuilder,将会得到一个如下的错误信息:
RNA2.scala:5: error: overriding method newBuilder in trait
TraversableLike of type => scala.collection.mutable.Builder[Base,RNA2];
method newBuilder in trait GenericTraversableTemplate of type
=> scala.collection.mutable.Builder[Base,IndexedSeq[Base]] has
incompatible type
class RNA2 private (val groups: Array[Int], val length: Int) ^
one error found(发现一个错误)
错误信息非常地长,并且很复杂,体现了容器(Collection)库错综复杂的组合。所以,最好忽略有关这些方法来源的信息,因为在这种情况下,它更多得是分散人的精力。而剩下的,则说明需要声明一个具有返回类型Builder[Base, RNA2]的newBuilder方法,但无法找到一个具有返回类型Builder[Base,IndexedSeq[Base]]的newBuilder方法。后者并不覆写前者。第一个方法——返回值类型为Builder[Base, RNA2]——是一个抽象方法,其在RNA2类中通过传递RNA2的类型参数给IndexedSeqLike,来以这种类型实例化。第二个方法的返回值类型为Builder[Base,IndexedSeq[Base]]——是由继承后的IndexedSeq类提供的。换句话说,如果没有声明一个以第一个返回值类型为返回值的newBuilder,RNA2类就是非法的。
改善了RNA2类中的实现之后,take、drop或filter方法现在便会按照预期执行:
scala> val rna2 = RNA2(A, U, G, G, T)
rna2: RNA2 = RNA2(A, U, G, G, T)
scala> rna2 take 3
res5: RNA2 = RNA2(A, U, G)
scala> rna2 filter (U !=)
res6: RNA2 = RNA2(A, G, G, T)
使用map(映射)和friends(友元)
然而,在容器中存在没有被处理的其他类别的方法。这些方法就不总会返回容器类型。它们可能返回同一类型的容器,但包含不同类型的元素。典型的例子就是map方法。如果s是一个Int的序列(Seq[Int]),f是将Int转换为String的方法,那么,s.map(f)将返回一个String的序列(Seq[String])。这样,元素类型在接收者和结果之间发生了改变,但容器的类型还是保持一致。
有一些其他的方法的行为与map类似,比如说flatMap、collect等,但另一些则不同。例如:++这个追加方法,它也可能因参数返回一个不同类型的结果——向Int类型的列表拼接一个String类型的列表将会得到一个Any类型的列表。至于这些方法如何适应RNA链,理想情况下应认为,在RNA链上进行碱基到碱基的映射将产生另外一个RNA链。(译者注:碱基为RNA链的“元素”)
scala> val rna = RNA(A, U, G, G, T)
rna: RNA = RNA(A, U, G, G, T)
scala> rna map { case A => T case b => b }
res7: RNA = RNA(T, U, G, G, T)
同样,用 ++ 方法来拼接两个RNA链应该再次产生另外一个RNA链。
scala> rna ++ rna
res8: RNA = RNA(A, U, G, G, T, A, U, G, G, T)
另一方面,在RNA链上进行碱基(类型)到其他类型的映射无法产生另外一个RNA链,因为新的元素有错误的类型。它只能产生一个序列而非RNA链。同样,向RNA链追加非Base类型的元素可以产生一个普通序列,但无法产生另一个RNA链。
scala> rna map Base.toInt
res2: IndexedSeq[Int] = Vector(0, 3, 2, 2, 1)
scala> rna ++ List("missing", "data")
res3: IndexedSeq[java.lang.Object] =
Vector(A, U, G, G, T, missing, data)
这就是在理想情况下应认为结果。但是,RNA2类并不提供这样的处理。事实上,如果你用RNA2类的实例来运行前两个例子,结果则是:
scala> val rna2 = RNA2(A, U, G, G, T)
rna2: RNA2 = RNA2(A, U, G, G, T)
scala> rna2 map { case A => T case b => b }
res0: IndexedSeq[Base] = Vector(T, U, G, G, T)
scala> rna2 ++ rna2
res1: IndexedSeq[Base] = Vector(A, U, G, G, T, A, U, G, G, T)
所以,即使生成的容器元素类型是Base,map和++的结果也永远不会是RNA链。如需改善,则需要仔细查看map方法的签名(或++,它也有类似的方法签名)。map的方法最初在scala.collection.TraversableLike类中定义,具有如下签名:
def map[B, That](f: A => B)
(隐含CBF:CanBuildFrom[修订版,B]):
这里的A是一个容器元素的类型,而Repr是容器本身的类型,即传递给实现类(例如 TraversableLike和IndexedSeqLike)的第二个参数。map方法有两个以上的参数,B和That。参数B表示映射函数的结果类型,同时也是新容器中的元素类型。That作为map的结果类型。所以,That表示所创建的新容器的类型。
对于That类型如何确定,事实上,它是根据隐式参数cbf(CanBuildFrom[Repr,B,That]类型)被链接到其他类型。这些隐式CanBuildFrom由独立的容器类定义。大体上,CanBuildFrom[From,Elem,To]类型的值可以描述为:“有这么一种方法,由给定的From类型的容器,使用Elem类型,建立To的容器。”
RNA链类的最终版本
final class RNA private (val groups: Array[Int], val length: Int)
extends IndexedSeq[Base] with IndexedSeqLike[Base, RNA] {
import RNA._
// 在IndexedSeq中必须重新实现newBuilder
override protected[this] def newBuilder: Builder[Base, RNA] =
RNA.newBuilder
// 在IndexedSeq中必须实现apply
def apply(idx: Int): Base = {
if (idx < 0 || length <= idx)
throw new IndexOutOfBoundsException
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
}
// (可选)重新实现foreach,
// 来提高效率
override def foreach[U](f: Base => U): Unit = {
var i = 0
var b = 0
while (i < length) {
b = if (i % N == 0) groups(i / N) else b >>> S
f(Base.fromInt(b & M))
i += 1
}
}
}
RNA伴生对象的最终版本
object RNA {
private val S = 2 // group中的比特(bit)数
private val M = (1 << S) - 1 // 用于隔离group的比特掩码
private val N = 32 / S // 一个Int中的group数
def fromSeq(buf: Seq[Base]): RNA = {
val groups = new Array[Int]((buf.length + N - 1) / N)
for (i <- 0 until buf.length)
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA(groups, buf.length)
}
def apply(bases: Base*) = fromSeq(bases)
def newBuilder: Builder[Base, RNA] =
new ArrayBuffer mapResult fromSeq
implicit def canBuildFrom: CanBuildFrom[RNA, Base, RNA] =
new CanBuildFrom[RNA, Base, RNA] {
def apply(): Builder[Base, RNA] = newBuilder
def apply(from: RNA): Builder[Base, RNA] = newBuilder
}
}
现在在RNA2序列链上的 map 和 ++ 的行为变得更加清晰了。由于没有能够创建RNA2序列的CanBuildFrom实例,因此在从trait InexedSeq继承的伴生对象上得到的CanBuildFrom成为了第二选择。这隐式地创建了IndexedSeqs,也是在应用map到RNA2的时候发生的情况。
为了解决这个缺点,你需要在RNA类的同伴对象里定义CanBuildFrom的隐式实例。该实例的类型应该是CanBuildFrom [RNA, Base, RNA] 。即,这个实例规定,给定一个RNA链和新元素类型Base,可以建立另一个RNA链容器。上述有关RNA链的两个代码以及其伴生对象展示了细节。相较于类RNA2有两个重要的区别。首先, newBuilder的实现,从RNA类移到了它的伴生对象中。RNA类中新的newBuilder方法只是转发这个定义。其次,在RNA对象现在有个隐式的CanBuildFrom值。要创建这样的对象你需要在CanBuildFrom trait中定义两个apply方法。同时,为容器RNA创建一个新的builder,但参数列表不同。在apply()方法只是简单地以正确的类型创建builder。相比之下,apply(from)方法将原来的容器作为参数。在适应动态类型的builder的返回值与接收者的动态类型一致非常有用。在RNA的情况下,这不会起作用,因为RNA是final类,所以静态类型的RNA任何接收者同时具有RNA作为其动态类型。这就是为什么apply(from)也只是简单地调用newBuilder ,忽略其参数。
这样,RNA类(final)以原本的类型实现了所有容器方法。它的实现需要一些协议支持。从本质上讲,你需要知道newBuilder 工厂放在哪里以及canBuildFrom的隐式实现。在有利方面,能够以相对较少的代码,得到大量自动定义的方法。另外,如果不打算在容器中扩展take,drop,map或++这样操作,可以不写额外的代码,并在类RNA1所示的实现上结束工作。
到目前为止,讨论集中在以定义新序列所需的最少方法来获得特定类型。但在实践中,可能需要在序列上添加新的功能,或重写现有的方法,以获得更好的效果。其中一个例子就是重写RNA类的foreach方法。foreach是RNA本身的一个重要方法,因为它实现了遍历容器。此外,容器的许多其他方法的实现依赖foreach。因此,投入一些精力来做优化方法的实现有意义。IndexedSeq的foreach方法的标准实现仅仅使用aplly来选取容器的中的第i个元素(i从0到容器长度-1)。因此,对RNA链的每一个元素,标准实现选择一个数组元素,并从中解开一个碱基(base)。而RNA类上重写的foreach要聪明得多。对于每一个选定的数组元素,它立刻对其中所包含的所有碱基应用给定的方法。因此,数组选择和位拆包的工作大大减少。
整合 sets与 map
在第二个实例中,将介绍如何将一个新的map类型整合到容器框架中的。其方式是通过使用关键字“Patricia trie”,实现以String作为类型的可变映射(mutable map)。术语“Patricia“实际上就是”Practical Algorithm to Retrieve Information Coded in Alphanumeric.”(检索字母数字编码信息的实用算法) 的缩写。思想是以树的形式存储一个set或者map,在这种树中,后续字符作为子树可以用唯一确定的关键字查找。例如,一个 Patricia trie存储了三个字符串 “abc”, “abd”, “al”, “all”, “xy” 。如下:
patricia 树的例子:
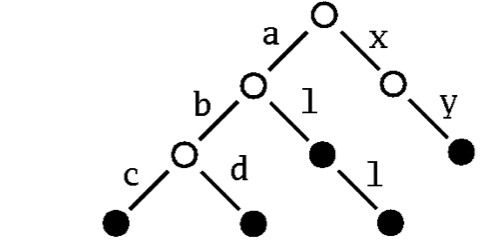
为了能够在trie中查找与字符串”abc“匹配的节点,只要沿着标记为”a“的子树,查找到标记为”b“的子树,最后到达标记为”c“的子树。如果 Patricia trie作为map使用,键所对应的值保存在一个可通过键定位的节点上。如果作为set,只需保存一个标记,说明set中存在这个节点。
使用Patricia tries的prefix map实现方式:
import collection._
class PrefixMap[T]
extends mutable.Map[String, T]
with mutable.MapLike[String, T, PrefixMap[T]] {
var suffixes: immutable.Map[Char, PrefixMap[T]] = Map.empty
var value: Option[T] = None
def get(s: String): Option[T] =
if (s.isEmpty) value
else suffixes get (s(0)) flatMap (_.get(s substring 1))
def withPrefix(s: String): PrefixMap[T] =
if (s.isEmpty) this
else {
val leading = s(0)
suffixes get leading match {
case None =>
suffixes = suffixes + (leading -> empty)
case _ =>
}
suffixes(leading) withPrefix (s substring 1)
}
override def update(s: String, elem: T) =
withPrefix(s).value = Some(elem)
override def remove(s: String): Option[T] =
if (s.isEmpty) { val prev = value; value = None; prev }
else suffixes get (s(0)) flatMap (_.remove(s substring 1))
def iterator: Iterator[(String, T)] =
(for (v <- value.iterator) yield ("", v)) ++
(for ((chr, m) <- suffixes.iterator;
(s, v) <- m.iterator) yield (chr +: s, v))
def += (kv: (String, T)): this.type = { update(kv._1, kv._2); this }
def -= (s: String): this.type = { remove(s); this }
override def empty = new PrefixMap[T]
}
Patricia tries支持非常高效的查找和更新。另一个良好的特点是,支持通过前缀查找子容器。例如,在上述的patricia tree中,你可以从树根处按照“a”链接进行查找,获得所有以”a“为开头的键所组成的子容器。
依据这些思想,来看一下作为Patricia trie的映射实现方式。这种map称为PrefixMap。PrefixMap提供了withPrefix方法,这个方法根据给定的前缀查找子映射(submap),其包含了所有匹配该前缀的键。首先,使用键来定义一个prefix map,执行如下。
scala> val m = PrefixMap("abc" -> 0, "abd" -> 1, "al" -> 2,
"all" -> 3, "xy" -> 4)
m: PrefixMap[Int] = Map((abc,0), (abd,1), (al,2), (all,3), (xy,4))
然后,在m中调用withPrefix方法将产生另一个prefix map:
scala> m withPrefix "a"
res14: PrefixMap[Int] = Map((bc,0), (bd,1), (l,2), (ll,3))
上面展示的代码表明了PrefixMap的定义方式。这个类以关联值T参数化,并扩展mutable.Map[String, T] 与 mutable.MapLike[String, T, PrefixMap[T]]。在RNA链的例子中对序列的处理也使用了这种模式,然后,为转换(如filter)继承实现类(如MapLike),用以获得正确的结果类型。
一个prefix map节点中含有两个可变字段:suffixes与value。value字段包含关联此节点的任意值,其初始化为None。suffixes字段包含从字符到PrefixMap值的映射(map),其初始化为空的map。
为什么要选择一种不可变map作为suffixes的实现方式?既然PrefixMap在整体上也是可变的,使用可变映射(map)是否更符合标准吗?这个问题的答案是,因为仅包含少量元素的不可变map,在空间和执行时间都非常高效。例如,包含有少于5个元素的map代表一个单独的对象。相比之下,就标准的可变map中的HashMap来说,即使为空时,也至少占用80bytes的空间。因此,如果普遍使用小容器,不可变的容器就优于可变的容器。在Patricia tries的例子中,预想除了树顶端节点之外,大部分节点仅包含少量的successor。所以在不可变映射(map)中存储这些successor效率很可能会更高。
现在看看映射(map)中第一个方法的实现:get。算法如下:为了获取prefix map里面和空字符串相关的值,简单地选取存储在树根节点上的任意值。另外,如果键字符串非空,尝试选取字符串的首字符匹配的子映射。如果产生一个map,继续去寻找map里面首个字符的之后的剩余键字符串。如果选取失败,键没有存储在map里面,则返回None。使用flatmap可以优雅地表示任意值上的联合选择。当对任意值ov,以及闭包f(其转而会返回任的值)进行应用时,如果ov和f都返回已定义的值,那么ov flatmap f将执行成功,否则ov flatmap f将返回None。
可变映射(map)之后的两个方法的实现是+=和-=。在prefixmap的实现中,它们按照其它两种方法定义:update和remove。
remove方法和get方法非常类似,除了在返回任何关联值之前,保存这个值的字段被设置为None。update方法首先会调用 withPrefix 方法找到需要被更新的树节点,然后将给定的值赋值给该节点的value字段。withPrefix 方法遍历整个树,如果在这个树中没有发现以这些前缀字符为节点的路径,它会根据需要创建子映射(sub-map)。
可变map最后一个需要实现的抽象方法是iterator。这个方法需要创建一个能够遍历map中所有键值对的迭代器iterator。对于任何给出的 prefix map,iterator 由如下几部分组成:首先,如果这个map中,在树根节点的value字段包含一个已定义的值Some(x),那么(“”, x)应为从iterator返回的第一个元素。此外,iterator需要串联存储在suffixes字段上的所有submap的iterator,并且还需要在这些返回的iterator每个键字符串的前面加上一个字符。进一步说,如果m是通过一个字符chr链接到根节点的submap ,并且(s, v)是一个从m.iterator返回的元素,那么这个根节点的iterator 将会转而返回(chr +: s, v)。在PrefixMap的iterator方法的实现中,这个逻辑可以非常简明地用两个for表达式实现。第一个for表达式在value.iterate上迭代。这表明Option值定义一个迭代器方法,如果Option值为None,则不返回任何元素。如果Option值为Some(x),则返回一个确切的元素x。
prefix map的伴生对象:
import scala.collection.mutable.{Builder, MapBuilder}
import scala.collection.generic.CanBuildFrom
object PrefixMap extends {
def empty[T] = new PrefixMap[T]
def apply[T](kvs: (String, T)*): PrefixMap[T] = {
val m: PrefixMap[T] = empty
for (kv <- kvs) m += kv
m
}
def newBuilder[T]: Builder[(String, T), PrefixMap[T]] =
new MapBuilder[String, T, PrefixMap[T]](empty)
implicit def canBuildFrom[T]
: CanBuildFrom[PrefixMap[_], (String, T), PrefixMap[T]] =
new CanBuildFrom[PrefixMap[_], (String, T), PrefixMap[T]] {
def apply(from: PrefixMap[_]) = newBuilder[T]
def apply() = newBuilder[T]
}
}
请注意,在PrefixMap中没有newBuilder方法的定义。这是没有必要的,因为maps和sets有默认的构造器,即MapBuilder类的实例。对可变映射来说,其默认的构造器初始时是一个空映射,然后使用映射的+= 方法连续增加元素。可变集合也类似。非可变映射和非可变集合的默认构造器则不同,它们使用无损的元素添加方法+,而非+=方法。
然而,为了构建合适的集合或映射,你都需要从一个空的集合或映射开始。empty方法提供了这样的功能,它是PrefixMap中最后定义的方法,该方法简单的返回一个新的PrefixMap。
现在我们来看看PrefixMap的伴生对象。事实上,并不是非要定义这种伴生对象,类PrefixMap自己就可以很好的完成它的功能。PrefixMap 对象的主要作用,是定义一些方便的工厂方法。它也定义了一个 CanBuildFrom,该方法可以让输入工作完成的更好。
其中有两个方法值得一提,它们是 empty 和 apply。同样的方法,在Scala的容器框架中的其他容器中都存在,因此在PrefixMap中定义它们也很合理。用这两种方法,你可以像写其他容器一样的编写PrefixMap:
scala> PrefixMap("hello" -> 5, "hi" -> 2)
res0: PrefixMap[Int] = Map((hello,5), (hi,2))
scala> PrefixMap.empty[String]
res2: PrefixMap[String] = Map()
另一个PrefixMap对象的成员是内置CanBuildFrom实例。它和上一节定义的CanBuildFrom目的相同:使得类似map等方法能返回最合适的类型。以PrefixMap的键值对映射函数为例,只要该函数生成串型和另一种类型组成的键值对,那么结果又会是一个PrefixMap。这里有一个例子:
scala> res0 map { case (k, v) => (k + "!", "x" * v) }
res8: PrefixMap[String] = Map((hello!,xxxxx), (hi!,xx))
给出的函数参数是一个PrefixMap res0的键值对绑定,最终生成串型值对。map的结果是一个PrefixMap,只是String类型替代了int类型。如果在PrefixMap中没有内置的canBuildFrom ,那么结果将是一个普通的可变映射,而不是一个PrefixMap。
小结
总而言之,如果你想要将一个新的collection类完全的融入到框架中,需要注意以下几点:
- 决定容器应该是可变的,还是非可变的。
- 为容器选择正确的基类trait
- 确保容器继承自适合的trait实现,这样它就能具有大多数的容器操作。
- 如果你想要map及类似的操作去返回你的容器类型的实例,那么就需要在类的伴生对象中提供一个隐式CanBuildFrom。
你现在已经了解Scala容器如何构建和如何构建新的容器类型。由于Scala丰富的抽象支持,新容器类型无需写代码就可以拥有大量的方法实现。
致谢
这些页面的素材改编自,由Odersky,Spoon和Venners编写的Scala编程第2版 。感谢Artima 对于出版的大力支持。